
Tematem dzisiejszego przykładu jest klasyfikacja strumieni danych. Bez zbędnych wstępów zapraszam do lektury.
Klasyfikacja strumieni danych
Strumienie danych
Strumień danych jest to uporządkowana sekwencja obiektów nieustannie napływająca w czasie. Wielkość takiego strumienia w teorii jest nieskończona, jednak w praktyce zakłada się, że zbiór równy lub przekraczający sto tysięcy obiektów można uznać za strumień danych. W wielu przypadkach podczas analizy strumienia danych, obiekty można odczytać tylko raz lub niewielką liczbę razy. Przetrzymywanie całego strumienia w pamięci jest niemożliwe i bardzo niepożądane. Podczas projektowania metod do klasyfikacji strumieni danych należy zwrócić szczególną uwagę na trzy poniższe problemy:
- Ograniczone zasoby obliczeniowe i pamięciowe, ponieważ dokonywana predykcja powinna się odbywać w dość szybkim czasie.
- Zjawisko zwane dryfem koncepcji, co oznacza zmiany w rozkładzie danych w trakcie ich napływu. Takie zjawisko może pogarszać jakość klasyfikacji.
- W niektórych strumieniach obiekty mogą przychodzić tak szybko, że pozyskanie wszystkich etykiet może być opóźnione, a czasem nawet niemożliwe.
Dryf koncepcji
Można wyodrębnić dwa rodzaje strumieni danych:
- Strumienie stacjonarne
- Strumienie dynamiczne
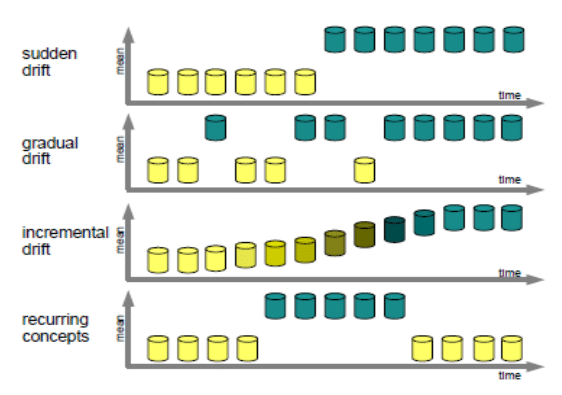
Stacjonarne strumienie to takie, które nie posiadają zmienności w czasie. Inaczej mówiąc jest to taki przypadek, gdzie na przestrzeni całego strumienia nie występują żadne zmiany w rozkładzie danych. Natomiast dynamiczne strumienie są ściśle związane ze zjawiskiem zwanym dryfem koncepcji. Dryf koncepcji charakteryzuje się tym, że rozkład przestrzeni cech ulega pewnym zmianom w czasie. Zmiany te są raczej nieokreślone i znacząco wpływają na pogorszenie jakości klasyfikacji danego klasyfikatora. W zależności od tego jaki typ dryfu koncepcji występuje, zmiany te mogą występować: nagle, inkrementalnie, rekurencyjnie i gradualnie. Poniższa ilustracja obrazuje wymienione typy dryfów.
Metody klasyfikacji niestacjonarnych strumieni danych
Zbliżamy się już trochę bardziej do praktycznej strony klasyfikacji strumieni danych. Na początku należy wskazać dwa rodzaje metod różniące się sposobem przetwarzania strumienia danych. W podejściu online, dane pobierane są obiekt po obiekcie i w taki też sposób metoda jest uczona oraz dokonuje predykcji. W podejściu bloków danych (ang. data chunk) dane pobierane są jako kilkanaście lub kilkaset obiektów na raz. Ilość obiektów jest zależna od tego jak duża zostanie ustalona wielkość jednego bloku danych. Tym drugim podejściem zajmiemy się w tym przykładzie.
Musimy jeszcze pamiętać, że głównym problemem jaki towarzyszy strumieniom danych jest dryf koncepcji. To zjawisko potrafi bardzo pogorszyć jakość metody podczas przeprowadzania eksperymentu. Aby sobie z tym radzić, powstało wiele różnych metod dedykowanych do klasyfikacji niestacjonarnych strumieni danych.
Detektor dryfu
Jeden z takich sposobów to detektor dryfu. Jest to algorytm, który dokonuje pewnej analizy danych lub jakości klasyfikatora w celu określenia czy wystąpił dryf. Najczęściej, kiedy dryf zostanie wykryty, to model nauczony na tych danych zostaje zresetowany i od nowa nauczony - przebudowany. Jednym z bardziej znanych przykładów jest metoda DDM. Detektor ten najpierw generuje sygnał ostrzegawczy, jeśli szacowany błąd plus dwukrotność jego odchylenia standardowego osiągnie określony poziom błędu. Następnie po osiągnięciu nowe przychodzące obiekty są zapamiętywane. Następnie gdy błąd spadnie poniżej progu ostrzeżenia, to ostrzeżenie jest traktowane jako fałszywy alarm i zapamiętane próbki są zapominane. Jednak gdy błąd wzrośnie i osiąga poziom uznany już jako poziom wystąpienia dryfu, to aktualny model jest usuwany i uczony jest nowy z użyciem przechowywanych przykładów. Zachęcam do lektury - Gama, Joao, et al. “Learning with drift detection.” Brazilian symposium on artificial intelligence. Springer, Berlin, Heidelberg, 2004.
Metody komitetowe
Istnieje również grupa metod, która bazuje na uczeniu przyrostowym oraz zapominaniu. Najczęściej tego typu metody są zespołami klasyfikatorów. Modele tworzące taki komitet uczone są na nowych blokach danych. Przykładowo n-ty blok danych tworzy n-ty model. Bardzo istotnym mechanizmem takich metod jest zapominanie, czyli usuwanie nadmiernych modeli. Najprostszym podejściem jest usuwanie najstarszego modelu z puli klasyfikatora. Inny sposób to odpowiednie ważenie na podstawie jakości lub jakości połączonej z zależnością czasową modelu. Jedną z takich metoda jest metoda SEA, która w bardzo prosty sposób usuwa z zespołu klasyfikatorów te modele, które uzyskują najniższą jakość. Również tutaj zachęcam do przeczytania - Street, W. Nick, and YongSeog Kim. “A streaming ensemble algorithm (SEA) for large-scale classification.” Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining. 2001.
Ewaluacja
W porównaniu do poprzednich przykładów proces ewaluacji trochę się zmieni. Po pierwsze, mając strumień danych nie możemy wykorzystać walidacji krzyżowej. Należy pamiętać o tym, że strumień danych jest pewną sekwencją obiektów, gdzie kolejność ma znaczenie. Pobieranie losowych próbek i zmiana ich kolejności jest niemożliwa. Zakładając, że chcemy nasz strumień przetwarzać jako bloki danych, można zastosować podejście test-then-train. Jest to taki sposób testowania, gdzie cały strumień dzielimy na bloki danych o określonej wielkości. Następnie używamy n-tego bloku danych, najpierw do przetestowania metody, a dopiero potem tymi danymi douczamy metodę. Wyjątkiem jest pierwszy blok danych.
Patrząc na metody do klasyfikacji strumieni danych od strony implementacyjnej, należy upewnić się, że użyta metoda posiada zdolność douczania. W przypadku algorytmów z bibliotek pochodnych od scikit-learn szukamy metody partial_fit(). W tym eksperymencie zostaną użyte dwie metody. Pierwsza to metoda MLPClassifier z biblioteki scikit-learn. Jest to klasyfikator wielowarstwowych sieci neuronowych. Druga metoda to metoda wspomniana już wcześniej SEA z biblioteki stream-learn. Jest to bardzo przydatna biblioteka, z której dzisiaj w wielu miejscach skorzystamy. Implementuje ona różne metody, algorytmy oraz generator danych potrzebne do przeprowadzania badań nad strumieniami danych. Autorami tej biblioteki jest doktor Ksieniewicz i magister Zyblewski.
Eksperyment
Przechodzimy już do samego eksperymentu. Na początku importujemy potrzebne funkcje, moduły i biblioteki.
import numpy as np
import strlearn as sl
from sklearn.neural_network import MLPClassifier
from sklearn.naive_bayes import GaussianNB
import matplotlib.pyplot as plt
Po pierwsze musimy wygenerować sobie strumień danych. Do tego wykorzystamy StreamGenerator z biblioteki stream-learn. Ustawiamy sobie ilość bloków danych (n_chunks) na 200, a ich wielkość na 500 obiektów w jednym. W sumie daje to nam 100 tysięcy obiektów. Liczba klas 2, liczba dryfów 1. Przy takich ustawieniach będzie to dryf nagły. Dla innych ustawień dryfów odsyłam do dokumentacji. Liczba atrybutów równa 10 i tradycyjnie jakiś random state.
stream = sl.streams.StreamGenerator(n_chunks=200,
chunk_size=500,
n_classes=2,
n_drifts=1,
n_features=10,
random_state=12345)
Następnie inicjujemy listę z metodami do klasyfikacji strumieni danych. Jedna to wspomniana już wcześniej metoda SEA posiadająca klasyfikator bazowy GuassianNB, a druga to metoda MLPClassifier z jedną warstwą ukrytą składającą się z 10 neuronów. Niżej tworzymy listę z nazwami tych metod, która przyda się później.
clfs = [
sl.ensembles.SEA(GaussianNB(), n_estimators=10),
MLPClassifier(hidden_layer_sizes=(10)),
]
clf_names = [
"SEA",
"MLP",
]
Teraz cztery szybkie, ale dość duże kroki. Najpierw wybieramy sobie metryki jakich chcemy użyć do ewaluacji. W tym wypadku znana z wcześniejszego przykładu metryka f1 score, czyli średnia harmoniczna precision i recall, oraz G-mean, czyli pierwiastek iloczynu recall i precision. Dodatkowo tworzymy sobie listę z nazwami metryk.
# Wybrana metryka
metrics = [sl.metrics.f1_score,
sl.metrics.geometric_mean_score_1]
# Nazwy metryk
metrics_names = ["F1 score",
"G-mean"]
W kolejnym kroku dokonujemy inicjalizacji ewaluatora. Podajemy jakiego typu ewaluator nas interesuje, w tym wypadku test-then-train, a jako parametr podajemy wybrane metryki lub metrykę.
# Inicjalizacja ewaluatora
evaluator = sl.evaluators.TestThenTrain(metrics)
Następnie uruchamiamy proces ewaluacji. Jako parametry do tej metody podajemy strumień stream i klasyfikatory/metody, które wcześniej zainicjowaliśmy clfs.
# Uruchomienie
evaluator.process(stream, clfs)
W ostatnim już kroku przechodzimy do rysowania uzyskanych wcześniej wyników. Najpierw sobie tworzymy puste wykresy. Następnie dla każdej metryki, w naszym przykładzie dwóch metryk, ustalamy tytuł wykresu i limit na osi y. Później w pętli dodajemy wartości uzyskane podczas ewaluacji wraz z etykietą klasyfikatora clf_names. Następnie podpisujemy osie wykresu i rysujemy legendę. Na sam koniec wyświetlamy wykres.
# Rysowanie wykresu
fig, ax = plt.subplots(1, len(metrics), figsize=(24, 8))
for m, metric in enumerate(metrics):
ax[m].set_title(metrics_names[m])
ax[m].set_ylim(0, 1)
for i, clf in enumerate(clfs):
ax[m].plot(evaluator.scores[i, :, m], label=clf_names[i])
plt.ylabel("Metric")
plt.xlabel("Chunk")
ax[m].legend()
plt.show()
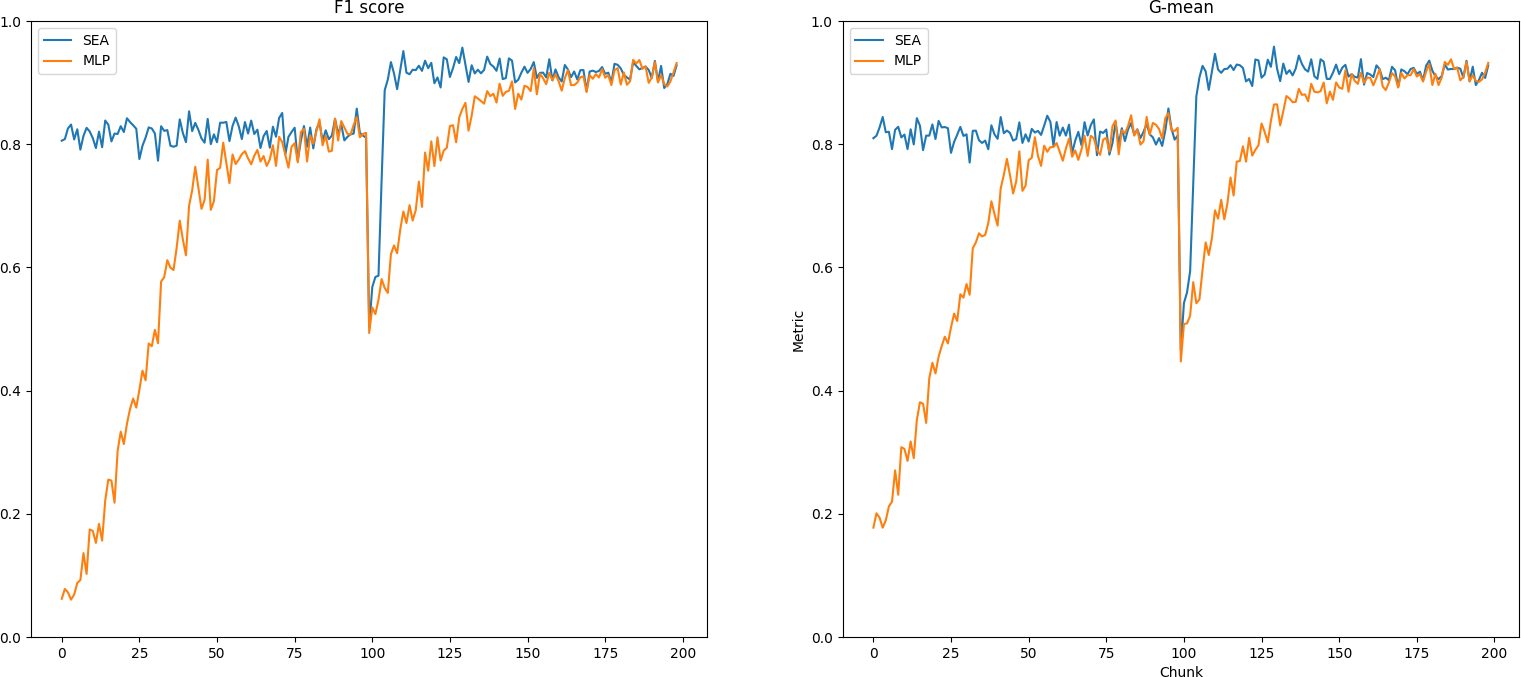
Na poniższych wykresach można zauważyć, że metoda SEA radzi sobie lepiej ze strumieniem danych z nagłym dryfem. Po lewej widoczna jest metryka F1 score, a po prawej G-mean. Patrząc na uzyskane wyniki widzimy, że najpierw MLP potrzebuje dużo więcej bloków danych, żeby zbudować dość wysoką jakość, porównywalną do SEA. Później po wystąpieniu dryfu koncepcji w setnym bloku danych ta jakość odbudowywuje się dużo dłużej niż w porównaniu do SEA. Dzieje się to za sprawą tego, że SEA posiada wbudowany mechanizm zapominania najgorszych modeli i cały zespół zostaje dość szybko przebudowany.
Z tego co mi wiadomo to ten materiał kończy cały cykl wpisów pod tytułem “Przykłady”. Gratuluję wszystkim, którzy dotarli do samego końca, a w nagrodę dedykuję tym osobom poniższą piosenkę: